最近我从云训练平台,训练了一个OCR识别的模型,然后训练平台给出的识别效果(应该就是测试集),非常的好,大概如下:
然后我就按照相关的要求,复制了文件夹mp_deployment_source到k230的目录下,放入了测试的图片,运行ocrrec_image.py进行测试,结果识别效果相差甚远,大概如下: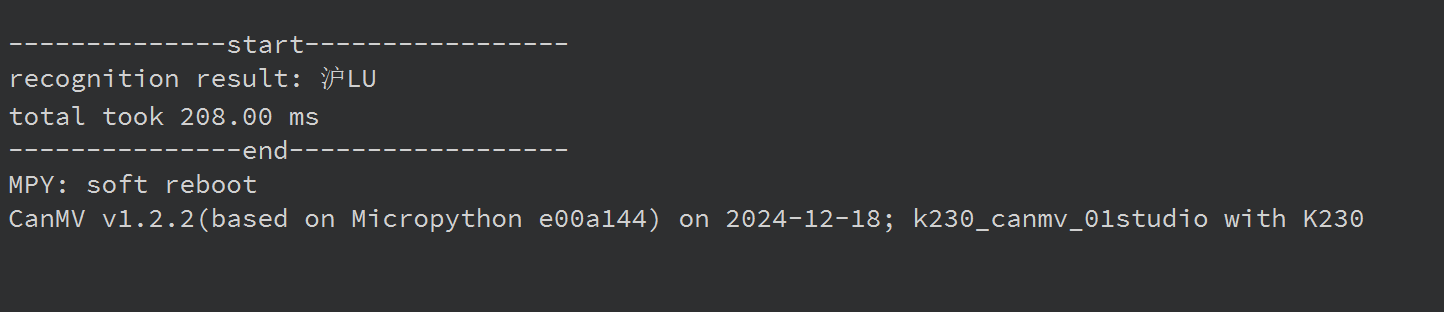
这里附上测试的图片:
根据之前技术人员的回复,我了解到可能是图片在传入模型的时候,因为大小不符,被压缩变形了,于是,我打开了deploy_config.json文件,修改参数,具体过程如下:
可以通过测试图片的参数看到,这里长宽是与测试图片一致的:
但是识别的效果还是不尽人意: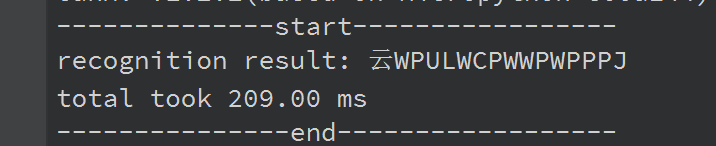
我有了解到,在.pt转到.onnx再转到.kmodel,模型的精准度会有一定损失,但是这个差别是否过大?还请大佬指教
训练平台给的效果和部署上去的效果相差过大的问题
Viewed 513
