这些东西网上查一下都很多的,你首先得明白这个YOLO格式是什么形式
从数据目录结构看,应该是如下这种:
my_dataset
|--- images
| |--- train
| |--- 0001.jpg
| |--- 0002.jpg
| |--- ...
| |--- val
| |--- 0001.jpg
| |--- ...
| |--- test
| |--- 0001.jpg
| |--- ...
|--- labels
| |--- train
| |--- 0001.txt
| |--- 0002.txt
| |--- ...
| |--- val
| |--- 0001.txt
| |--- ...
| |--- test
| |--- 0001.txt
| |--- ...
data.yaml
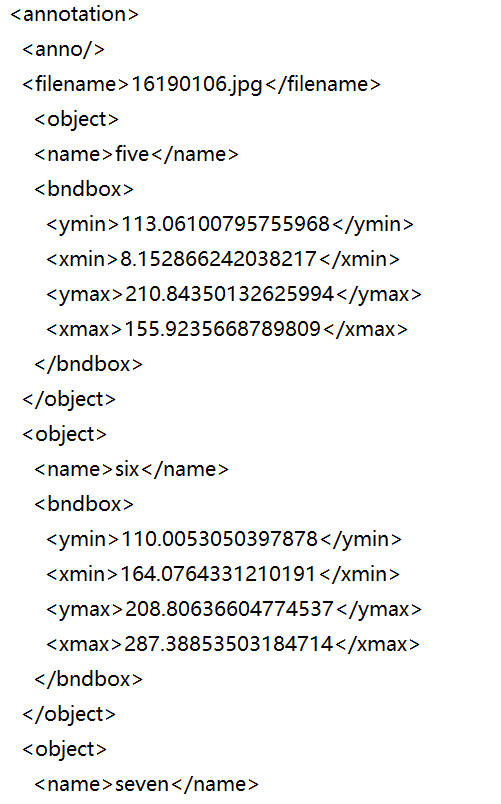
images目录下肯定是图片,labels目录下是标注框,那你肯定要把xml转换成txt。每张图片对应一个同名的txt文件,txt文件中的格式如下:
txt中可以有多行,每行表示一个标注框,格式为:<class_id> <x_center> <y_center> <box_width> <box_height>,其中:
class_id:类别索引(从0开始,与data.yaml中的类别顺序一致)。
x_center, y_center:边界框中心点坐标,归一化为图像尺寸的比例值,范围0~1,也就是需要对框的中心点x坐标/图片宽度,中心点y坐标/图片高度。
box_width, box_height:边界框宽高,归一化比例值,范围0~1,也就是需要对框宽度/图片宽度,框高度/图片高度。
这里给你一个脚本,把xml转换成txt,然后你再把数据分成上面树状图的格式:
import os
import xml.etree.ElementTree as ET # 用于解析XML文件(VOC标注格式)
import cv2 # 用于读取图像文件,获取图像尺寸
# 设置路径
xml_dir = 'xml' # 存放VOC XML标注文件的目录
image_dir = 'images' # 存放图片的目录,用于读取图片尺寸
label_dir = 'labels' # YOLO标签输出目录,转换后的txt文件将保存在这里
labels_file = 'labels.txt' # 包含类别名称的文件,每行一个类别名称
def load_class_names(labels_file):
""" 从 labels.txt 文件中加载类别名称列表 """
with open(labels_file, 'r') as f:
class_names = [line.strip() for line in f.readlines()] # 去除每行首尾空白字符
return class_names
# 加载类别名称,并创建类别名到类别ID的映射字典
class_names = load_class_names(labels_file)
class_mapping = {name: i for i, name in enumerate(class_names)} # {'person': 0, 'car': 1, ...}
def get_image_size(image_path):
""" 使用 OpenCV 读取图片的宽和高 """
img = cv2.imread(image_path) # 读取图像
if img is None:
raise ValueError(f"无法读取图片或图片不存在: {image_path}")
height, width = img.shape[:2] # OpenCV返回的shape是(height, width, channels)
return width, height
def convert_voc_to_yolo(xml_file, image_file, txt_file):
"""
将单个VOC格式的XML文件转换为YOLO格式的txt文件
:param xml_file: XML标注文件路径
:param image_file: 对应的图像文件路径
:param txt_file: 输出的YOLO标签文件路径
"""
tree = ET.parse(xml_file)
root = tree.getroot()
# 优先从XML文件中读取图像尺寸
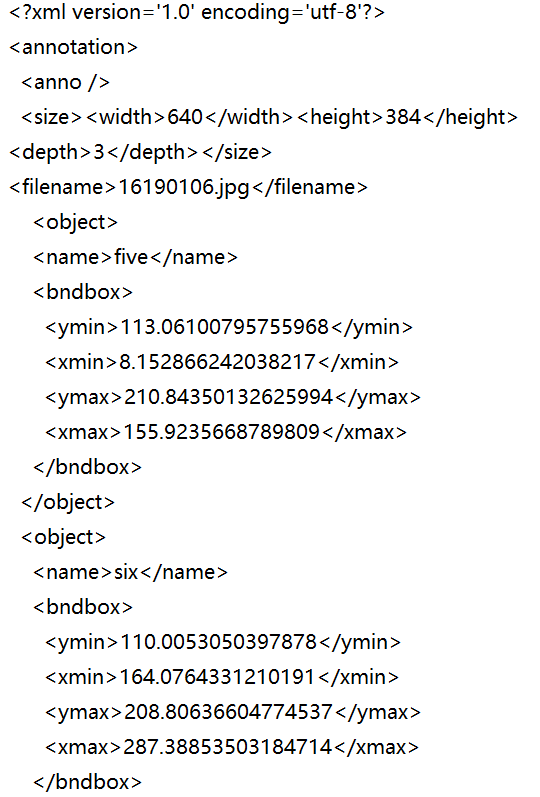
size_elem = root.find('size')
if size_elem is not None and size_elem.find('width') is not None and size_elem.find('height') is not None:
width = int(size_elem.find('width').text)
height = int(size_elem.find('height').text)
else:
# 如果XML中没有尺寸信息,则从图片中读取
width, height = get_image_size(image_file)
# 打开txt文件准备写入
with open(txt_file, 'w') as f:
for obj in root.findall('object'): # 遍历每个目标对象
cls = obj.find('name').text # 获取类别名称
# 如果类别不在预定义的类别列表中,跳过该对象
if cls not in class_mapping:
continue
cls_id = class_mapping[cls] # 获取对应的类别ID
# 获取边界框坐标
bbox = obj.find('bndbox')
xmin = int(bbox.find('xmin').text)
ymin = int(bbox.find('ymin').text)
xmax = int(bbox.find('xmax').text)
ymax = int(bbox.find('ymax').text)
# 转换为YOLO格式:归一化中心坐标 + 宽高
x_center = (xmin + xmax) / 2.0 / width
y_center = (ymin + ymax) / 2.0 / height
w = (xmax - xmin) / float(width)
h = (ymax - ymin) / float(height)
# 保留6位小数,避免浮点数精度问题
x_center = round(x_center, 6)
y_center = round(y_center, 6)
w = round(w, 6)
h = round(h, 6)
# 写入YOLO格式的标签文件
f.write(f"{cls_id} {x_center} {y_center} {w} {h}\n")
def convert_all():
""" 将指定目录下的所有VOC XML文件转换为YOLO格式的txt文件 """
if not os.path.exists(label_dir):
os.makedirs(label_dir) # 如果输出目录不存在则创建
# 遍历XML目录下的所有文件
for xml_file in os.listdir(xml_dir):
if not xml_file.endswith('.xml'):
continue # 只处理.xml文件
base_name = os.path.splitext(xml_file)[0] # 获取文件名(不含扩展名)
image_path = None
# 查找对应的图片文件,尝试常见的图像扩展名
for ext in ['.jpg', '.jpeg', '.png', '.bmp']:
img_path = os.path.join(image_dir, base_name + ext)
if os.path.exists(img_path):
image_path = img_path
break
if image_path is None:
print(f"警告: 没有找到 {xml_file} 对应的图片,跳过。")
continue
# 构建输出txt文件路径
txt_file = os.path.splitext(xml_file)[0] + '.txt'
txt_path = os.path.join(label_dir, txt_file)
# 执行转换
convert_voc_to_yolo(xml_path, image_path, txt_path)
print(f"已转换: {xml_file} -> {txt_file}")
if __name__ == '__main__':
convert_all() # 主程序入口,开始批量转换
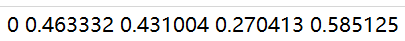

你好,你是用什么python软件执行的,我用vs code执行不了这个