问题描述
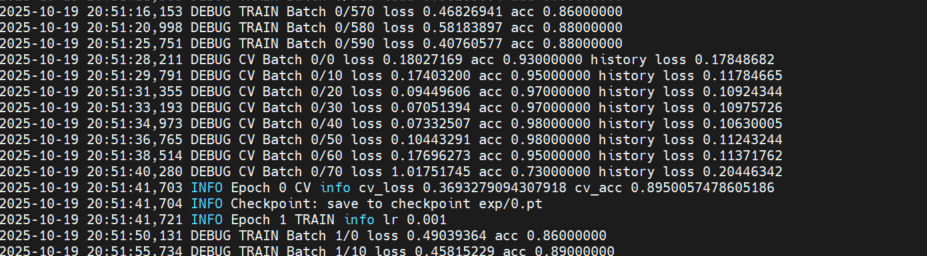
使用https://github.com/kendryte/K230_training_scripts/tree/main/end2end_kws_doc的例程进行语音唤醒kws模型训练,训练中的模型,在第一轮acc就异常,一直为1,训练后的模型无法准确识别关键词。请问是什么原因?
复现步骤
使用https://github.com/kendryte/K230_training_scripts/tree/main/end2end_kws_doc进行语音唤醒关键词识别模型训练,K230 kws 语音唤醒,使用自定义的唤醒词,
硬件板卡
01 studio mini k230
软件版本
https://github.com/kendryte/K230_training_scripts/tree/main/end2end_kws_doc