问题描述
当「轻量化大模型」遇上「高性价比终端」,这场边缘 AI 的革命已悄然开始。如何用 K230 打造你的专属智能终端,让每个设备都拥有「对话大脑」?
本文尝试将轻量化的大语言模型部署至边缘侧芯片K230上,探索在资源受限的嵌入式环境中实现本地化的文本多轮交互与语音理解能力,为边缘智能终端提供可落地、低成本、数据隐私性好的人机交互方案。
一、环境搭建
烧写镜像
1.硬件准备
K230 01Studio 开发板
购买链接:
https://item.taobao.com/item.htm?id=821397288809

2.软件准备
K230 LLM 需要专门定制的Linux镜像,主要是将 CMA 由50%提高到90%(2GB * 90% = 1.8GB),另外内置了两个 LLM demo ( qwen_chat 和 voice_assistant )。
Linux 镜像和 demo 下载链接:
https://www.kendryte.com/zh/resource/images,k230
$ md5sum k230_ai_assistant.tgz
$ cat k230_ai_assistant.tgz.md5
$ tar xzf k230_ai_assistant.tgz
$ ls -l k230_ai_assistant
3.烧写
使用 USB 烧录工具
请参考:https://www.kendryte.com/answer/questions/10010000000008370
riscv64 Toolchain
若不须修改程序, 可跳过此步骤, 直接运行镜像自带的 k230 LLM 程序
-
下载工具链:
Xuantie-900-gcc-linux-6.6.0-glibc-x86_64-V2.10.1-20240712.tar.gz -
解压到 /path/to/k230_ai_assistant/src/toolchain 目录
$ cd /path/to/k230_ai_assistant/src
$ wget -c https://occ-oss-prod.oss-cn-hangzhou.aliyuncs.com/resource//1721095219235/Xuantie-900-gcc-linux-6.6.0-glibc-x86_64-V2.10.1-20240712.tar.gz
$ mkdir toolchain
$ tar xzf Xuantie-900-gcc-linux-6.6.0-glibc-x86_64-V2.10.1-20240712.tar.gz -C toolchain/
$ ls -l toolchain

二、文本对话
使用模型(Qwen 2.5)
Qwen2.5 是阿里巴巴推出的轻量化大模型系列,专为边缘计算与端侧 AI设计,通过模型压缩与优化技术,在保持高性能的同时实现低资源消耗,推动大模型从云端向 IoT 终端、嵌入式设备的规模化落地。
github地址:
https://github.com/QwenLM/Qwen2.5
官方文档:
https://qwen.readthedocs.io/zh-cn/latest/index.html
所有开放权重的模型都是稠密的、decoder-only的语言模型,提供多种不同规模的版本,包括:
Qwen2.5: 0.5B, 1.5B, 3B, 7B, 14B, 32B, 以及 72B;
Qwen2.5-Coder: 1.5B, 7B, 以及即将推出的 32B;
Qwen2.5-Math: 1.5B, 7B, 以及 72B。
由于 K230 最大支持 2GB 内存, 这里我们选择 Qwen2.5 0.5B 模型,我们已经转换好kmodel,放到 demo 程序下面了!
程序编译
若不须修改程序, 可跳过此步骤, 直接运行镜像自带的 k230 LLM 程序
直接执行qwen_chat目录下的riscv64_build.sh脚本即可
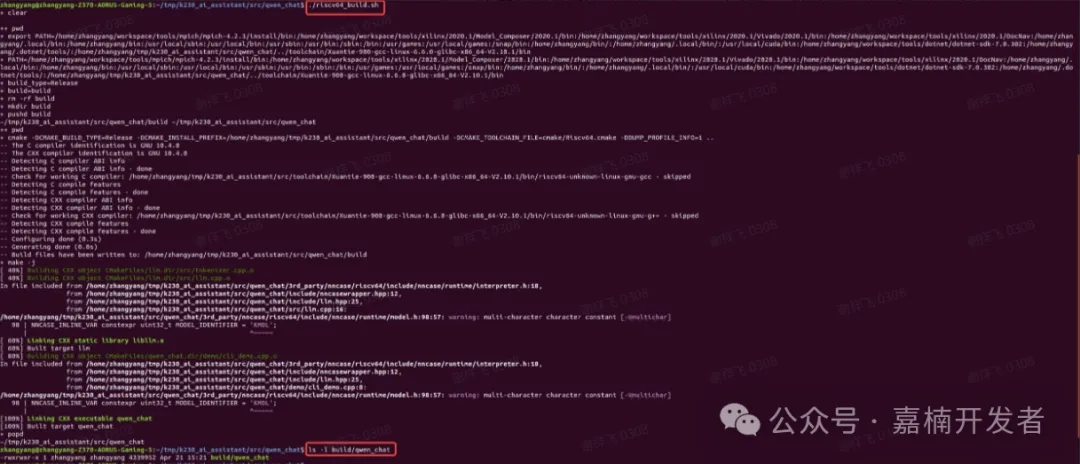
将build/qwen_chat覆盖到板子的/app/qwen_chat/qwen_chat即可。
上板运行
目前限制最大输入+输出为512个 token。输出过程中,输入+输出 token >512后会自动截断
执行 run.sh 启动程序,由于模型较大,需要等待片刻
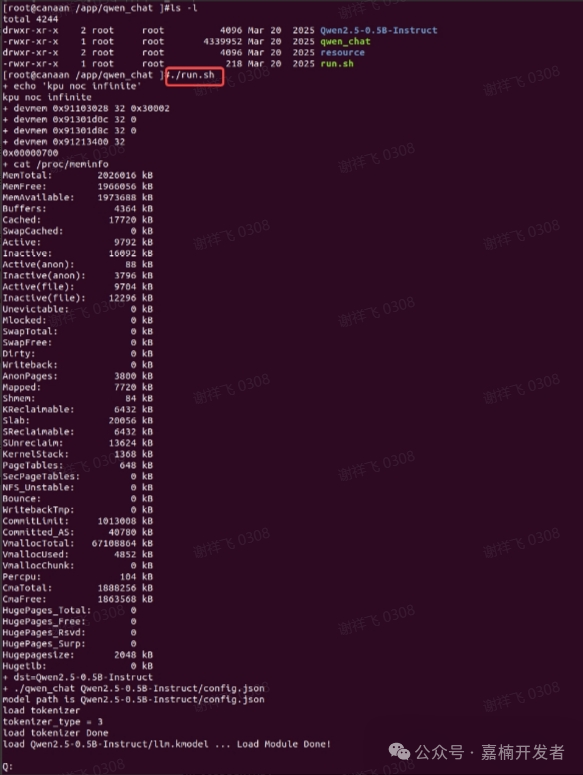
启动成功后, 在 <Q:> 后输入问题,支持中/英文,程序检测到回车后,开始推理,终端打印问题答案,最后输出性能信息等。

输入"/exit",退出程序。
问答社区【请增加 QWen 标签】:
https://www.kendryte.com/answer/