问题描述
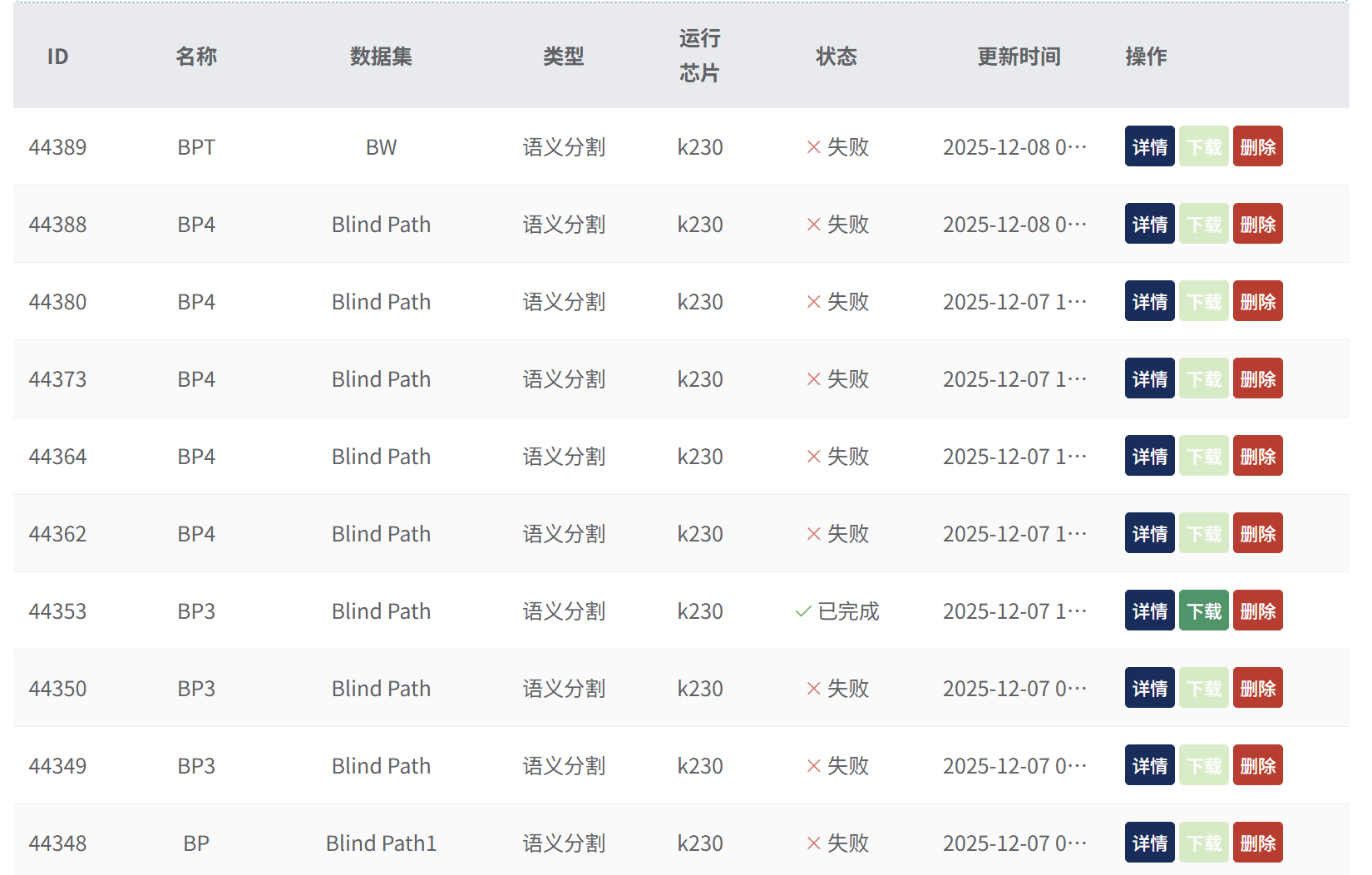
语义分割任务提示Docker容器操作异常,重新多次创建训练任务不起作用,共包含508张图片,ID为44350,如图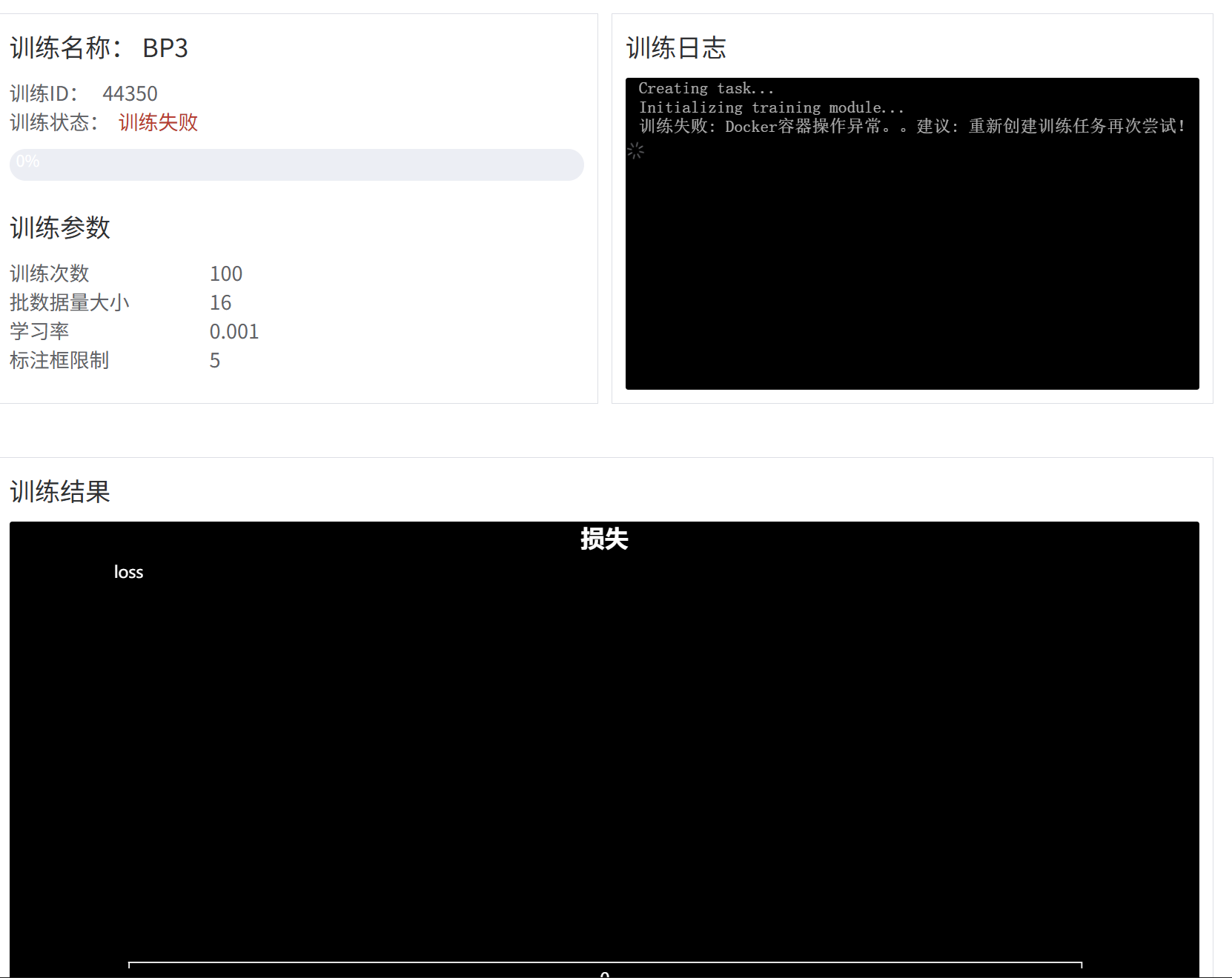 !
!
先不要重新创建了,等我们查一下
你好,将下面的代码创建一个python脚本,丢到解压后下载数据集目录中,执行代码,会生成对应的json文件在annotations目录下,然后选中images、annotations、labels.txt右键压缩为zip,然后重新创建数据集上传就可以了。
import os
import json
import cv2
import numpy as np
# 输入输出目录
IMAGE_DIR = "images"
MASK_DIR = "masks"
OUTPUT_DIR = "annotations"
LABEL_FILE = "labels.txt"
os.makedirs(OUTPUT_DIR, exist_ok=True)
def load_class_names(label_file):
"""从 labels.txt 读取类别,从第2行开始作为有效类别"""
if not os.path.exists(label_file):
raise FileNotFoundError(f"未找到 {label_file}")
with open(label_file, "r", encoding="utf-8") as f:
lines = [line.strip() for line in f.readlines() if line.strip()]
if len(lines) <= 1:
raise ValueError("labels.txt 至少需要两行:background + 至少一个类别")
# 跳过第一行 background,后面每行依次对应 mask 中的 1,2,3,...
class_dict = {idx: name for idx, name in enumerate(lines[1:], start=1)}
print("读取到的类别映射:")
for cid, name in class_dict.items():
print(f" {cid} -> {name}")
return class_dict
# 加载类别名称(从文件)
CLASS_NAMES = load_class_names(LABEL_FILE)
def mask_to_polygons(mask, class_id):
"""根据 mask 的类别提取 polygon 点"""
binary = np.uint8(mask == class_id)
contours, _ = cv2.findContours(binary, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
polys = []
for contour in contours:
if contour.shape[0] < 3:
continue
pts = contour.reshape(-1, 2).astype(float).tolist()
polys.append(pts)
return polys
def process_one_image(img_name):
img_path = os.path.join(IMAGE_DIR, img_name)
mask_path = os.path.join(MASK_DIR, os.path.splitext(img_name)[0] + ".png")
if not os.path.exists(mask_path):
print(f"跳过: 未找到 mask {mask_path}")
return
img = cv2.imread(img_path)
mask = cv2.imread(mask_path, cv2.IMREAD_UNCHANGED)
h, w = mask.shape
shapes = []
unique_ids = np.unique(mask)
for cid in unique_ids:
if cid == 0:
continue # 跳过背景
if cid not in CLASS_NAMES:
print(f"警告: 在 {img_name} 中发现未定义类别 {cid}")
continue
polys = mask_to_polygons(mask, cid)
for poly in polys:
shapes.append({
"label": CLASS_NAMES[cid],
"points": poly,
"group_id": None,
"shape_type": "polygon",
"flags": {}
})
# 构建 LabelMe JSON
json_dict = {
"version": "5.0.5",
"flags": {},
"shapes": shapes,
"imagePath": img_name,
"imageData": None,
"imageHeight": h,
"imageWidth": w
}
out_path = os.path.join(OUTPUT_DIR, os.path.splitext(img_name)[0] + ".json")
with open(out_path, "w", encoding="utf-8") as f:
json.dump(json_dict, f, ensure_ascii=False, indent=2)
print(f"已生成: {out_path}")
def main():
for name in sorted(os.listdir(IMAGE_DIR)):
if name.lower().endswith((".jpg", ".jpeg", ".png")):
process_one_image(name)
if __name__ == "__main__":
main()
