问题描述
你是否想过,用一块性价比超高的开发板,就能搭建属于自己的智能语音助手?
现在,K230 开发板携手开源多模态大模型mini-omni,让每个人都能轻松实现端到端语音交互!从语音输入到智能应答,再到语音输出,全流程本地部署,打造你的专属 AI 助手不再是梦!
mini-omni 核心亮点抢先看
✅ 端到端语音交互:直接接收语音输入,生成语音回答,无需额外 ASR/TTS 工具,真正「听懂你说的,说出你要的」
✅ 轻量化部署:0.5B 参数规模,完美适配 K230 算力;
✅ 多模态融合:支持语音、文本混合输入,未来还将拓展视觉能力,打造会听、会说、会看的全能助手;
✅ 开源免费:代码 + 模型全开源,开发者可自由定制对话逻辑、唤醒词、语音风格。
一、环境搭建
烧写镜像
1、K230 01Studio开发板 (记得内存需要选择2GB)
购买链接:
https://item.taobao.com/item.htm?id=821397288809
2、音箱或者耳机

3、软件准备
K230 LLM需要专门定制的Linux镜像,另外内置了两个LLM demo(qwen_chat和voice_assistant)。
Linux镜像和demo下载链接:
https://www.kendryte.com/zh/resource/images,k230
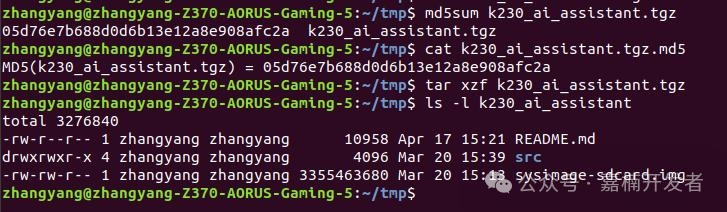
$ md5sum k230_ai_assistant.tgz
$ cat k230_ai_assistant.tgz.md5
$ tar xzf k230_ai_assistant.tgz
$ ls -l k230_ai_assistant
4、烧写
使用 USB 烧录工具,参考推文:
https://www.kendryte.com/answer/questions/10010000000008370
riscv64 Toolchain
若不须修改程序, 可跳过此步骤, 直接运行镜像自带的k230 LLM程序
-
下载
Xuantie-900-gcc-linux-6.6.0-glibc-x86_64-V2.10.1-20240712.tar.gz -
解压到
/path/to/k230_ai_assistant/src/toolchain目录
$ cd /path/to/k230_ai_assistant/src/
$ wget -c https://occ-oss-prod.oss-cn-hangzhou.aliyuncs.com/resource//1721095219235/Xuantie-900-gcc-linux-6.6.0-glibc-x86_64-V2.10.1-20240712.tar.gz
$ mkdir toolchain
$ tar xzf Xuantie-900-gcc-linux-6.6.0-glibc-x86_64-V2.10.1-20240712.tar.gz -C toolchain/
$ ls -l toolchain

二、运行语音对话机器人
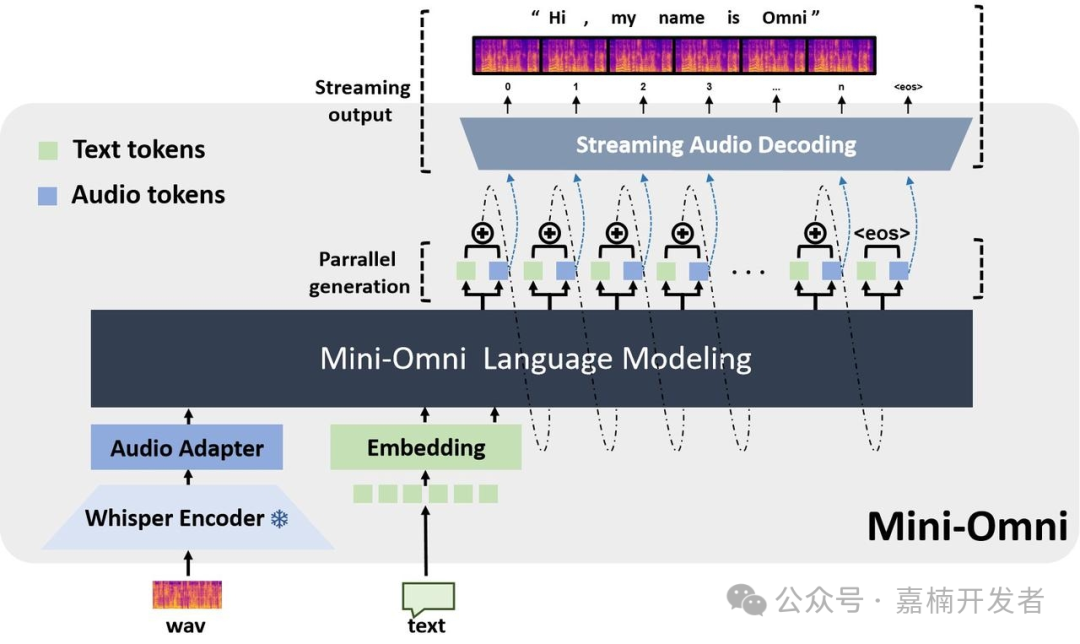
使用模型(mini-omni)
语音对话机器人的多模态模型, 0.5B的目前使用mini-omni模型
-
mini-omni论文 :
https://arxiv.org/abs/2408.16725 -
mini-omni github:
https://github.com/gpt-omni/mini-omni
语音对话机器人的完整 pipeline 包括:
- VAD: 人声提取
- log Mel: 语音特征提取
- Whisper Small Encoder: 转换原始音频信号到高级语义表征
- litGPT: 轻量化开源GPT实现
- espeak-ng: 文本转语音合成器
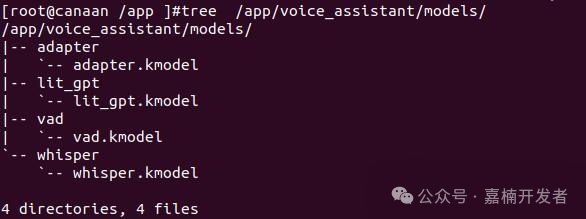
mini-omni 模型. 我们已经转换好对应的 kmodel, 位置如下:
/app/voice_assistant/models/
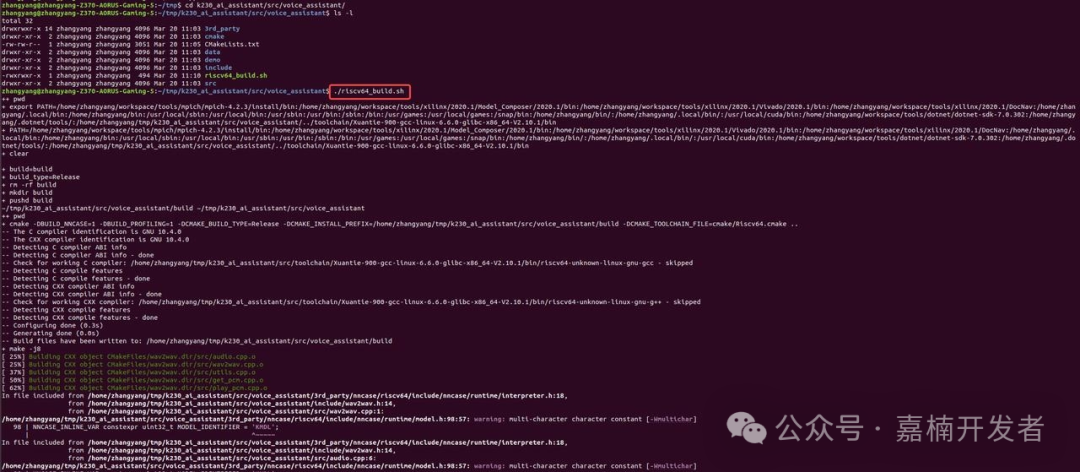
程序编译
若不须修改程序, 可跳过此步骤, 直接运行镜像自带的k230 LLM程序
直接执行 voice_assistant 目录下的 riscv64_build.sh 脚本即可
将 build/voice_assistant 覆盖到 K230 01Studio 板子的 /app/voice_assistant/voice_assistant 即可.
上板运行
运行方法:
执行 run.sh 启动程序, 由于模型较多且较大, 需要等待一段时间
-
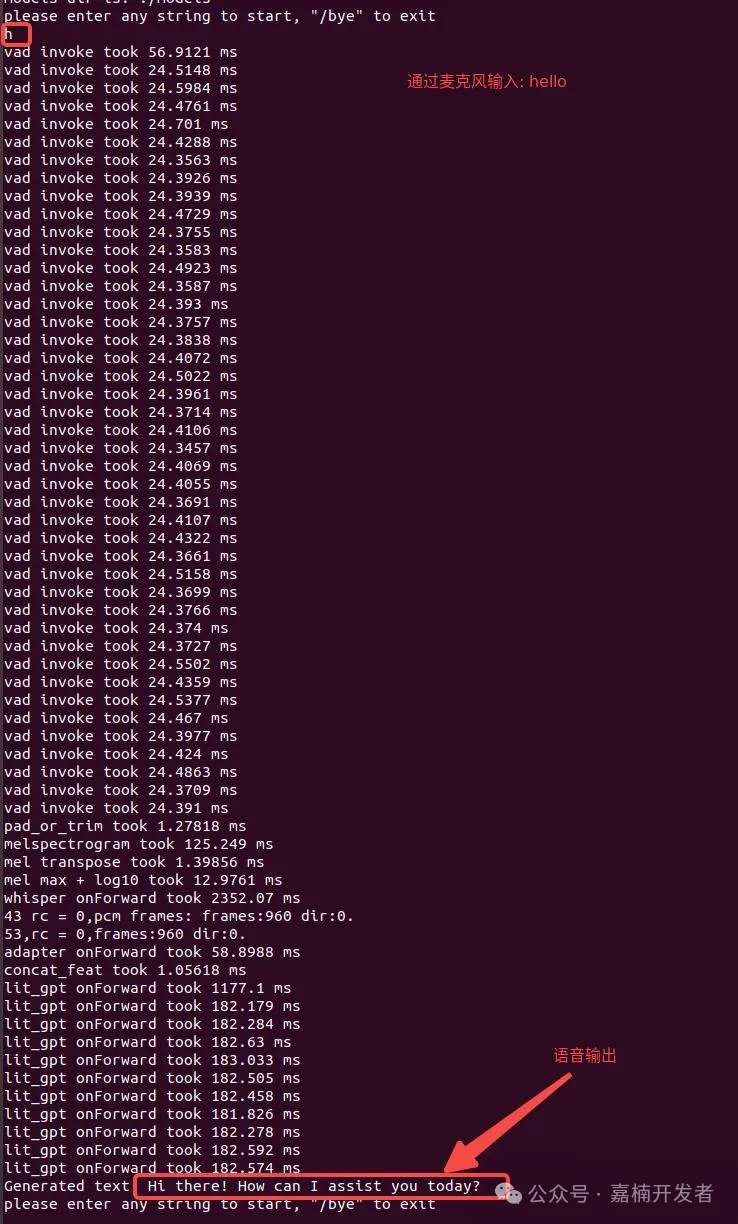
启动成功后, 输入任意字符, 回车, 即可靠近麦克风, 用英文提问. 程序检测到人声结束, 开始推理, 终端打印相关信息, 音箱输出问题答案
-
输入 , 退出程序
